At first glance, ZFS snapshots, bookmarks, and checkpoints may seem similar. Let's explore what these features are, how they differ, and example use cases for each.
Snapshots
Snapshots are a read-only, point-in-time view of an entire dataset; browsing a snapshot means everything will look exactly as it was when the snapshot was created. This is useful both for making backups (e.g. retaining different versions of a file as it changes over time) but also for syncing data between datasets or pools. For more on how ZFS snapshots work, see this previous article.
Bookmarks
A bookmark is similar to a snapshot in that it represents a point-in-time, but unlike a snapshot, it takes up virtually no space at all since it just records a small amount of metadata. We can use the following example to see how this is useful.
Let's look at tank/example before doing anything:
1root@demo:~# zfs list -o space tank/example
2NAME AVAIL USED USEDSNAP USEDDS USEDREFRESERV USEDCHILD
3tank/example 1.16G 600M 500M 100M 0B 0B
4
5root@demo:~# zfs list -t snapshot -r tank/example
6NAME USED AVAIL REFER MOUNTPOINT
7tank/example@snap1 100M - 100M -
8tank/example@snap2 100M - 100M -
9tank/example@snap3 100M - 100M -
10tank/example@snap4 100M - 100M -
11tank/example@snap5 100M - 100M -
At this point, tank/example consumes 600MB of unique data:
- 5x snapshots, each with 100MB of unique data
- 100MB of unique data in the live dataset
Let's replicate this all to another dataset, tank/backup, using syncoid:
1root@demo:~# syncoid -r tank/example tank/backup
2INFO: Sending oldest full snapshot tank/example@snap1 (~ 100.2 MB) to new target filesystem:
3 100MiB 0:00:00 [ 124MiB/s] [==================================================>] 100%
4INFO: Updating new target filesystem with incremental tank/example@snap1 ... syncoid_demo_2025-06-09:23:39:15-GMT00:00 (~ 500.9 MB):
5 501MiB 0:00:09 [50.3MiB/s] [==================================================>] 100%
At this point, the two datasets should be identical:
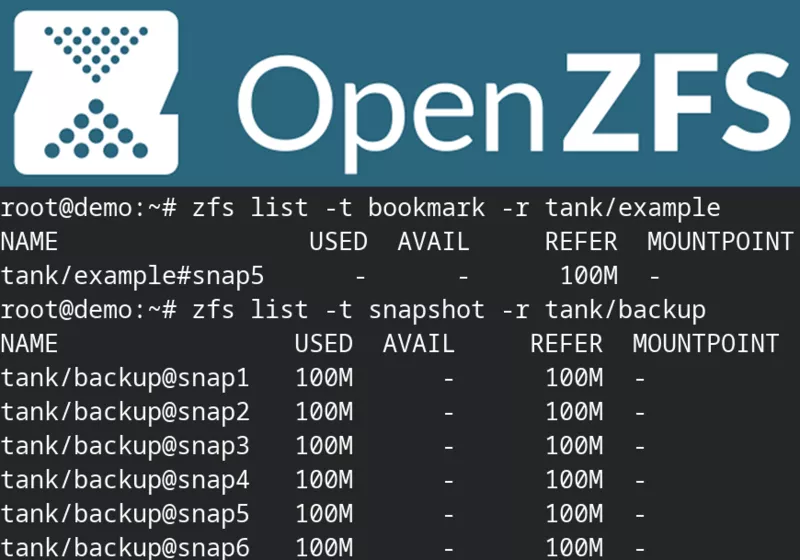
1root@demo:~# zfs list -t snapshot -r tank
2NAME USED AVAIL REFER MOUNTPOINT
3tank/backup@snap1 100M - 100M -
4tank/backup@snap2 100M - 100M -
5tank/backup@snap3 100M - 100M -
6tank/backup@snap4 100M - 100M -
7tank/backup@snap5 100M - 100M -
8tank/example@snap1 100M - 100M -
9tank/example@snap2 100M - 100M -
10tank/example@snap3 100M - 100M -
11tank/example@snap4 100M - 100M -
12tank/example@snap5 100M - 100M -
Let's create a new snapshot on the source dataset and create 100MB of new data:
1root@demo:~# zfs snapshot tank/example@snap6
2
3root@demo:~# dd if=/dev/urandom of=/tank/example/file1.txt bs=1M count=100
4100+0 records in
5100+0 records out
6104857600 bytes (105 MB, 100 MiB) copied, 1.51721 s, 69.1 MB/s
7
8root@demo:~# zfs list -o space tank/example
9NAME AVAIL USED USEDSNAP USEDDS USEDREFRESERV USEDCHILD
10tank/example 491M 701M 600M 100M 0B 0B
Now we have 100MB that is only present in tank/example but not present in tank/backup. As long as there is a common ancestor snapshot on both datasets, we can continue to sync new data like this as it comes in. However, if the source dataset is low on space, it may be impractical to keep a long history of snapshots around. This is where bookmarks come in handy - you can create a bookmark of a snapshot on the source, delete the snapshot, and still replicate new data to the destination (since the bookmark contains the reference metadata that the destination needs to know where to start replicating from). Let's give it a try:
1root@demo:~# zfs bookmark tank/example@snap5 tank/example#snap5
2
3root@demo:~# zfs list -t bookmark -r tank/example
4NAME USED AVAIL REFER MOUNTPOINT
5tank/example#snap5 - - 100M -
6
7root@demo:~# zfs destroy tank/example@snap1
8root@demo:~# zfs destroy tank/example@snap2
9root@demo:~# zfs destroy tank/example@snap3
10root@demo:~# zfs destroy tank/example@snap4
11root@demo:~# zfs destroy tank/example@snap5
At this point, tank/example consumes a lot less space:
1root@demo:~# zfs list -o space -r tank/example
2NAME AVAIL USED USEDSNAP USEDDS USEDREFRESERV USEDCHILD
3tank/example 891M 200M 100M 100M 0B 0B
Nevertheless, we can still replicate the new data from it:
1root@demo:~# syncoid -r tank/example tank/backup
2Sending incremental tank/example#'snap5' ... snap6 (~ UNKNOWN):
3Sending incremental tank/example@snap6 ... syncoid_demo_2025-06-09:23:50:18-GMT00:00 (~ 100.2 MB):
4 100MiB 0:00:00 [ 103MiB/s] [==================================================>] 100%
5
6root@demo:~# zfs list -t snapshot -r tank
7NAME USED AVAIL REFER MOUNTPOINT
8tank/backup@snap1 100M - 100M -
9tank/backup@snap2 100M - 100M -
10tank/backup@snap3 100M - 100M -
11tank/backup@snap4 100M - 100M -
12tank/backup@snap5 100M - 100M -
13tank/backup@snap6 100M - 100M -
14tank/example@snap6 100M - 100M -
15
16root@demo:~# zfs list -o space -r tank
17NAME AVAIL USED USEDSNAP USEDDS USEDREFRESERV USEDCHILD
18tank 891M 901M 0B 24K 0B 901M
19tank/backup 891M 701M 600M 100M 0B 0B
20tank/example 891M 200M 100M 100M 0B 0B
If space on the source dataset is a concern, or ZFS replication might get disrupted for longer than the source dataset's retention period, consider using bookmarks to avoid problems replicating from one dataset (or pool) to another.
Checkpoints
Think of a checkpoint as a single snapshot of an entire pool; all datasets are snapshotted atomically in the checkpoint, which allows you to rollback everything if needed. One common use case for checkpoints is before an OS or other software upgrade when running / on ZFS - you can make a checkpoint, run the upgrade, and if anything breaks easily rollback to your known-good system:
1root@demo:~# zpool checkpoint tank
2
3root@demo:~# zpool status tank
4 pool: tank
5 state: ONLINE
6 scan: scrub repaired 0B in 00:00:03 with 0 errors on Sun Jun 8 00:24:04 2025
7checkpoint: created Mon Jun 9 23:58:10 2025, consumes 85.5K
Unlike snapshots and bookmarks, only a single checkpoint can exist on a pool at any given time. Moreover, these are not intended to be long-lived and your pool may quickly lose free space since everything in the checkpoint must be retained. Therefore, once your testing is complete, remove the checkpoint:
1root@demo:~# zpool checkpoint -d tank
Conclusion
ZFS snapshots, bookmarks, and checkpoints are all useful tools to help manage changing data in datasets and pools. Consider how you can design your system to maximize free space while also retaining the ability to replicate data and rollback to an earlier point-in-time if needed.