Understanding how much space a ZFS dataset is using is not as straightforward as it first seems, but let's dive in and decipher how to calculate used space on ZFS.
The first thing to understand is how a copy-on-write filesystem with snapshots works. Let's use an example with timestamps to illustrate this:
| Time | Action | Used Space |
|---|---|---|
| 10:00 | the dataset is created and is empty | 0MB |
| 10:01 | a 100MB file, file1.txt, is added to the dataset |
100MB |
| 10:02 | a snapshot, snap1, is created |
100MB |
| 10:03 | 10MB of the contents of file1.txt is changed |
110MB |
| 10:04 | a snapshot, snap2, is created |
110MB |
| 10:05 | another 100MB file, file2.txt, is added to the dataset |
210MB |
| 10:06 | snap1 is destroyed |
200MB |
| 10:07 | file1.txt is deleted |
200MB |
| 10:08 | snap2 is deleted |
100MB |
This probably seems straightforward until 10:03, when you edit file1.txt and change 10MB of the contents. At this point, snap1 contains the old 10MB of data in the file and the live dataset contains the new 10MB. Then when snap2 is created, it contains the new 10MB. Moreover, both snap1 and snap2 contain the remaining 90MB in the file that is unchanged; this is shared between both snapshots. At 10:06 when snap1 is destroyed, all the data that was only referenced by snap1 is removed (the original 10MB of file1.txt) and that space is freed up. Similarly at 10:07 when file1.txt is deleted, the used space remains the same because file1.txt still exists in snap2.
A useful way to think about this is to treat snapshots like hardlinks in a filesystem - as long as at least one hardlink exists to a file, it continues to exist.
Once we have a more complex set of files, and a large number of snapshots, it can be hard to determine which files are referenced by each snapshot. Fortunately, ZFS properties for each dataset make this easier to decipher. You can use zfs get all name/of/dataset to see all of them, but let's examine a few of them below.
First, let's create a zpool, enable compression, create a dataset, and cd into it:
1root@demo:~# dd if=/dev/zero of=/root/pool.img bs=1M count=2000
22000+0 records in
32000+0 records out
42097152000 bytes (2.1 GB, 2.0 GiB) copied, 27.8838 s, 75.2 MB/s
5root@demo:~# zpool create tank /root/pool.img
6root@demo:~# zfs set compression=on tank
7root@demo:~# zfs create tank/example
8root@demo:~# zfs list -r tank
9NAME USED AVAIL REFER MOUNTPOINT
10tank 146K 1.75G 24K /tank
11tank/example 24K 1.75G 24K /tank/example
12root@demo:~# zpool list tank
13NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
14tank 1.88G 198K 1.87G - - 0% 0% 1.00x ONLINE -
15root@demo:~# cd /tank/example
Useful Attributes: compression and compressratio
If you're following these best practices, you will have enabled compression on your zpool. This means that the actual amount of space used by a file is probably smaller than the filesize itself since the data will be stored compressed. You can see if compression is enabled and if so which algorithm is used by checking the compression property. Moreover, you can see how well the algorithm is doing at compressing your specific data using compressratio. Keep this in mind when looking at other ZFS properties below - unless otherwise noted they are telling you the compressed size of the data.
If data can't be compressed, then it will appear to be the size you expect it to be and compressratio will be equal to 1.00x. For example, a file with completely random content cannot be compressed:
1root@demo:/tank/example# dd if=/dev/urandom of=file1.txt bs=1M count=100
2100+0 records in
3100+0 records out
4104857600 bytes (105 MB, 100 MiB) copied, 2.21311 s, 47.4 MB/s
5root@demo:/tank/example# ls -lh
6total 78M
7-rw-r--r-- 1 root root 100M Jul 18 03:00 file1.txt
8root@demo:/tank/example# zfs get logicalused tank/example
9NAME PROPERTY VALUE SOURCE
10tank/example logicalused 100M -
11root@demo:/tank/example# zfs list -r tank
12NAME USED AVAIL REFER MOUNTPOINT
13tank 100M 1.65G 24K /tank
14tank/example 100M 1.65G 100M /tank/example
15root@demo:/tank/example# zfs get compressratio tank/example
16NAME PROPERTY VALUE SOURCE
17tank/example compressratio 1.00x -
Compare that to a newly-created file that can be compressed:
1root@demo:/tank/example# ls -lh file2.txt
2-rw-r--r-- 1 root root 66M Jul 18 03:11 file2.txt
3root@demo:/tank/example# zfs get compressratio tank/example
4NAME PROPERTY VALUE SOURCE
5tank/example compressratio 1.13x -
6root@demo:/tank/example# zfs list -r tank/example
7NAME USED AVAIL REFER MOUNTPOINT
8tank/example 147M 1.61G 147M /tank/example
In this case, a 66MB file only takes up 47MB of space due to the compression.
Useful Attributes: used, usedbysnapshots, and usedbydataset
The used attribute represents the total amount of used space for a dataset. This is useful for getting a quick total but doesn't distinguish between data present in snapshots and live data actually present now in the dataset. This distinction is crucial when thinking about free space - let's say you have a 2GB zpool and want to store a 100MB tarball in it that is regenerated every hour. If you start taking snapshots of this dataset hourly, you'll completely fill up the 2GB zpool after 20 hours. Let's try this out and catch it before we run out of free space:
1root@demo:/tank/example# zfs list -t snapshot -r tank/example
2NAME USED AVAIL REFER MOUNTPOINT
3tank/example@snap1 100M - 100M -
4tank/example@snap2 100M - 100M -
5tank/example@snap3 100M - 100M -
6tank/example@snap4 100M - 100M -
7tank/example@snap5 100M - 100M -
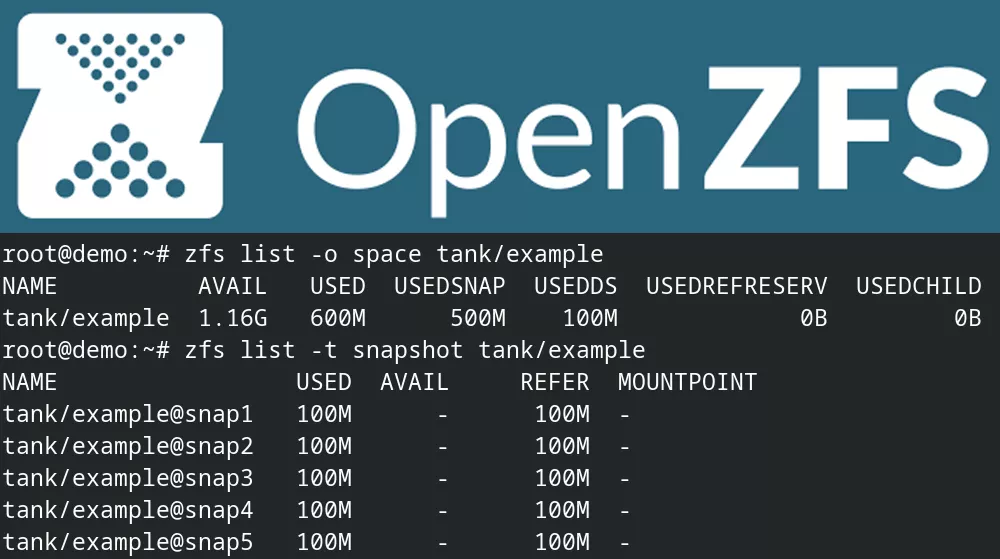
At this point, we've taken 5 snapshots and each contains 100MB of unique data. Moreover, there's a new 100MB file in the dataset that was created after snap5, so there's a total of 600MB used:
1root@demo:/tank/example# zfs list tank/example
2NAME USED AVAIL REFER MOUNTPOINT
3tank/example 600M 1.16G 100M /tank/example
To make this a lot clearer, let's look at the dataset using -o space, which shows usedbysnapshots and usedbydataset alongside used:
1root@demo:/tank/example# zfs list -o space tank/example
2NAME AVAIL USED USEDSNAP USEDDS USEDREFRESERV USEDCHILD
3tank/example 1.16G 600M 500M 100M 0B 0B
Excellent! We can now see that 500MB of the 600MB used is all from files that no longer exist in the live dataset but only exist in snapshots. The actual live data is only 100MB. This allows you to adjust your snapshot policy to avoid filling up your zpool.
Conversely, you could have a dataset which has data that changes infrequently. In this case, usedbysnapshots will be small and usedbydataset will be large.
Useful Attribute: logicalused
If you use zfs send and zfs receive (or a tool like syncoid) to sync a copy of your dataset to another zpool, you might be surprised to find that used doesn't match; this may have to do with different settings (e.g. compression, recordsize, etc) between the datasets or perhaps a significant amount of fragmentation on the source zpool. In any event, it can be useful to compare the datasets using the logicalused property, which ignores factors like compression.
Deleting snapshots to free up space
Since multiple snapshots can point at the same data, it can be hard to determine how much space would be freed up by deleting a particular snapshot. Fortunately, you can simulate what would happen (and how much space would be freed) by running zfs destroy -nv:
1root@demo:/tank/example# zfs destroy -nv tank/example@snap1
2would destroy tank/example@snap1
3would reclaim 100M
Conclusion
While used space on ZFS isn't as simple as looking up a single value, ZFS properties for each dataset provide an illuminating view into where space is being used and how to free up space.