ZFS datasets are a powerful and flexible organizational tool that let you easily and quickly structure your data, monitor size over time, and take backups. Learn more about how to create and manage ZFS datasets in this article.
We'll use Ubuntu as the operating system and sanoid and syncoid for easily sending and receiving ZFS snapshots. However, any flavor of Linux or FreeBSD should work too, though the installation steps will differ. To install ZFS on Ubuntu, simply run sudo apt-get install zfsutils-linux.
You can give ZFS a try without formatting a real disk; simply create an image file and format it as ZFS:
1# create a 1000MB image file
2dd if=/dev/zero of=/tmp/zfs.img bs=1M count=1000
3
4# create a zpool called "food" on this image file
5zpool create food /tmp/zfs.img
What is a dataset?
A traditional filesystem like ext4 runs inside one disk partition. This is a simple structure, but inflexible if the growth of your data changes over time and you later want to rearrange your data. For example, imagine you created 2 partitions, a 10GB one for vegetables and a 5GB one for fruit. Perhaps you initially expect your vegetable data to grow much more quickly, but what if the reverse happens? You may end up with 5GB of fruit data, and now the partition has to be resized in order to make room. While this operation is possible, it will probably involve moving other data on the disk somewhere else and require the fruit partition to be unmounted temporarily. Using ZFS datasets, you can dynamically move the space where it is needed, no resizing or shuffling of data required.
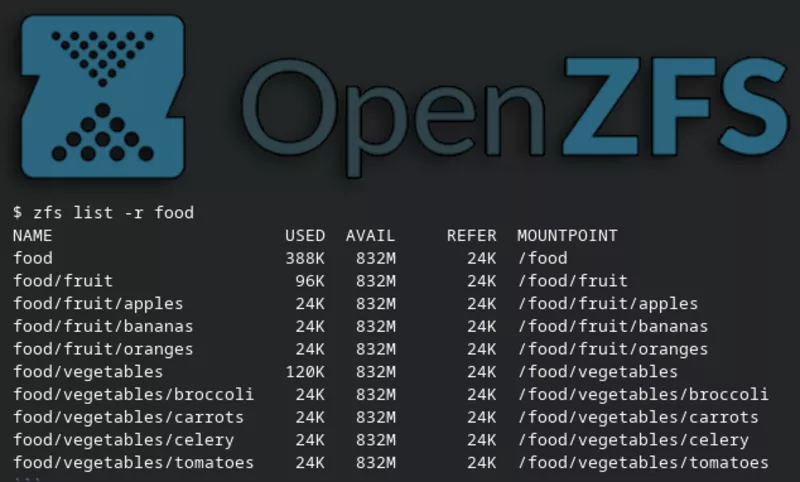
Think of a zpool as a collection of dynamic filesystems (aka datasets) that can be nested within each other, resized, snapshotted, etc. For example, a zpool of food could look like this:
1$ zfs list -r food
2NAME USED AVAIL REFER MOUNTPOINT
3food 388K 832M 24K /food
4food/fruit 96K 832M 24K /food/fruit
5food/fruit/apples 24K 832M 24K /food/fruit/apples
6food/fruit/bananas 24K 832M 24K /food/fruit/bananas
7food/fruit/oranges 24K 832M 24K /food/fruit/oranges
8food/vegetables 120K 832M 24K /food/vegetables
9food/vegetables/broccoli 24K 832M 24K /food/vegetables/broccoli
10food/vegetables/carrots 24K 832M 24K /food/vegetables/carrots
11food/vegetables/celery 24K 832M 24K /food/vegetables/celery
12food/vegetables/tomatoes 24K 832M 24K /food/vegetables/tomatoes
If you wanted to manage your apples, you can cd /food/fruit/apples and similar for each of the other foods. If you later decide that tomatoes are really a fruit, you can move them simply with zfs rename food/vegetables/tomatoes food/fruit/tomatoes.
How do you configure a dataset?
Each dataset has a number of properties that you can get or set on it using zfs get and zfs set respectively. Some examples of what you can do with properties:
- Compression: Save space on the data stored in your dataset by enabling compression; there are a number of algorithms to choose from, and you can recursively enable compression on child datasets by simply setting it on the parent dataset. Note that changing compression settings doesn't affect existing data in the dataset, only new data written from then on. For an example, let's enable compression for all vegetable data:
1$ zfs set compression=lz4 food/vegetables
2$ zfs get compression -r food
3NAME PROPERTY VALUE SOURCE
4food compression off default
5food/fruit compression off default
6food/fruit/apples compression off default
7food/fruit/bananas compression off default
8food/fruit/oranges compression off default
9food/vegetables compression lz4 local
10food/vegetables/broccoli compression lz4 inherited from food/vegetables
11food/vegetables/carrots compression lz4 inherited from food/vegetables
12food/vegetables/celery compression lz4 inherited from food/vegetables
13food/vegetables/tomatoes compression lz4 inherited from food/vegetables
- Encryption: You can enable ZFS encryption on a dataset easily using a password
- Quotas: If you want to prevent a particular dataset from growing larger than a certain size, you can use a quota.
- Mountpoint: You can configure where a dataset is mounted, even in a directory completely unrelated to other datasets in the pool, using
zfs set mountpoint=/path/to/the/new/mountpoint the/dataset/name. - Custom Information: You can even store custom information about a dataset in User Properties. For example, to store the color of the apples:
1$ zfs set custom:color=red food/fruit/apples
2$ zfs get custom:color food/fruit/apples
3NAME PROPERTY VALUE SOURCE
4food/fruit/apples custom:color red local
How do you backup datasets?
Even more powerful than any of the above features is ZFS's ability to take, send, and delete snapshots. While you can do this directly with ZFS commands, I highly recommend the combination of sanoid and syncoid to fully automate this process.
Sanoid
Sanoid lets you define a schedule on which to take the snapshots and how many of them to keep around (e.g. 12 hourly, 7 daily, 4 weekly, 6 monthly, and 1 yearly):
It will automatically clean up extraneous old snapshots as they accumulate, and take new ones on the prescribed schedule; simply configure a cron job to run sanoid frequently:
10 * * * * /usr/local/bin/sanoid --cron
Syncoid
Syncoid lets you easily copy these snapshots to another server, for example to make backups. The beauty of syncoid is the syntax is as easy to use as cp or rsync, making it very simple even if you're recursively syncing a whole zpool of datasets and all their snapshots. For example, to sync all of this food data to a backup server called mybackups:
1syncoid -r food user@mybackups:food
Again, you should configure a cron job to run it regularly.
Conclusion
ZFS is a powerful filesystem with a long history and proven track record. Its combination of features and simplicity makes organizing and backing up your data easy and gives you flexibility to adapt as your needs change over time.