
There are multiple layers of caching involved when writing a file before it makes it to permanent storage on your disk. This becomes even more complicated with a virtual machine which has its own set of caches. Let's explore how exactly writes make it safely to your disk, both on a physical server and a VM. For simplicity, we'll assume that all servers in this article are using the ext4 filesystem (though most modern filesystems operate in a similar manner).
Write Cache With a Physical Server
First, we need to understand how a physical server handles writes to a disk. In this scenario, there are a couple of layers of caching:
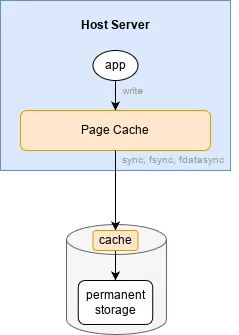
When an application issues a write, it is first written to the page cache, a special location in RAM. Writing to RAM is much faster than writing to a disk, so this is the ideal first location to hold the data from a speed perspective. However, if power is lost, the data in RAM will be lost. "Dirty" data in the page cache is then periodically flushed to permanent storage on the disk. This gets trickier when you consider that many disks have their own internal volatile write cache, which might further delay writing data to permanent storage or rearrange the order of write operations. There are several pieces that make this all work together:
- the journal, which ensures that data is only considered valid in the filesystem once it is actually on permanent storage
- the
commitmount option, which determines how frequently data is automatically flushed to permanent storage - the
barriermount option, which ensures that the journal metadata is written after the data
Let's explore each of these in more detail.
The Journal
Modern filesystems have the concept of a journal that records the information about a write in a separate place on disk to ensure that the data is fully written before the transaction is considered complete. For an overview of how the journal works, read section 42.3 of OSTEP.
The Commit Mount Option
The ext4 filesystem has the commit mount option (reference) which determines how often "dirty" data from the page cache will be flushed to permanent storage:
1commit=nrsec (*) Ext4 can be told to sync all its data and metadata
2 every 'nrsec' seconds. The default value is 5 seconds.
3 This means that if you lose your power, you will lose
4 as much as the latest 5 seconds of work (your
5 filesystem will not be damaged though, thanks to the
6 journaling). This default value (or any low value)
7 will hurt performance, but it's good for data-safety.
8 Setting it to 0 will have the same effect as leaving
9 it at the default (5 seconds).
10 Setting it to very large values will improve
11 performance
By default, this is set to 5 seconds (check /proc/mounts to see if a non-default value is set on your mountpoint) meaning your journal and metadata are being flushed to permanent storage every 5 seconds.
Write Barriers
As noted above, many disks have their own internal write cache which may reorder write operations. While this may be more efficient, it could result in the journal operations being written out of order and a corrupt entry would result (see the OSTEP description of this problem above). To prevent this from happening, the barrier mount option enables write barriers which tell the disk controller that writes before the barrier must all be completed before writes after the barrier. This ensures that the journal will not be corrupted.
Even More Detail
Going into more detail, the maximum possible time between when data is first written and when the data and its metadata are automatically written to disk is actually the combination of commit and the dirty_expire_centisecs kernel tunable, as described here and here:
it is reasonable to assume that data gets automatically persistent in dirty_expire_centisecs + commit_interval time
The reason for this is very recent "dirty" data isn't considered old enough for this automatic flushing operation until it is dirty_expire_centisecs old (the default is 30 seconds). This is done to prevent wasting expensive writes on transient data, avoid filesystem fragmentation, and reduce CPU usage. As described here, any of the following can trigger a flush to permanent storage:
When free memory falls below a specified threshold to regain memory consumed by dirty pages.
When dirty data lasts until a specific period. The oldest data is written back to the disk to ensure that dirty data does not remain dirty indefinitely.
When a user process invokes the sync() and fsync() system calls. This is an on-demand write back.
It's important to understand that all of the above functionality with commit is only for applications which do not issue their own sync(), fsync(), or fdatasync() calls as they are writing data. Many applications, in particular database engines like PostgreSQL, do this all the time:
When PostgreSQL writes to disk, it executes one of the system fsync calls (fsync or fdatasync) to flush that data to disk. By default, the cache on hard disks and disk controllers are assumed to be volatile: when power fails, data written there will be lost. Since that can result in filesystem and/or database corruption when it happens, fsync in Linux issues a write barrier that forces all data onto physical disk. That will flush the write cache on both RAID and drive write caches.
These syscalls trigger an on-demand writeback, and immediately flush the data to permanent storage.
Write Cache With a VM
This gets more complex in the case of a VM, where the guest has its own page cache:
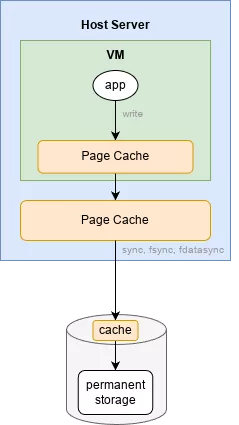
Fortunately, QEMU/KVM provides several options for which caches to enable and disable. The default value is writeback, which at first glance might seem unsafe, but let's review why it is in fact sufficient:
writeback - Writeback uses the host page cache. Writes are reported to the guest as completed when they are placed in the host cache. Cache management handles commitment to the storage device. The guest's virtual storage adapter is informed of the writeback cache and therefore expected to send flush commands as needed to manage data integrity.
writethrough - Writes are reported as completed only when the data has been committed to the storage device. The guest's virtual storage adapter is informed that there is no writeback cache, so the guest does not need to send flush commands to manage data integrity.
none - The host cache is bypassed, and reads and writes happen directly between the hypervisor and the storage device. Because the actual storage device may report a write as completed when the data is still placed in its write queue only, the guest's virtual storage adapter is informed that there is a writeback cache. This mode is equivalent to direct access to the host's disk.
unsafe - Similar to the writeback mode, except all flush commands from the guests are ignored. Using this mode implies that the user prioritizes performance gain over the risk of data loss in case of a host failure. This mode can be useful during guest installation, but not for production workloads.
directsync - Writes are reported as completed only when the data has been committed to the storage device and the host cache is bypassed. Similar to writethrough, this mode can be useful for guests that do not send flushes when needed.
This means that as long as the guest is using the commit and barrier mount options, and it is therefore sending fdatasync syscalls to force that data to permanent storage, it's safe. Let's verify this for ourselves.
Testing a VM
I created a new QEMU/KVM VM using the latest LTS Ubuntu Cloud image using libvirt. I configured the disk as follows:
1<disk type='file' device='disk'>
2 <driver name='qemu' type='qcow2' cache='writeback' discard='unmap'/>
3 <source file='/var/lib/libvirt/images/demo.qcow2' index='2'/>
4 <backingStore/>
5 <target dev='vda' bus='virtio'/>
6 <alias name='virtio-disk0'/>
7 <address type='pci' domain='0x0000' bus='0x05' slot='0x00' function='0x0'/>
8</disk>
As seen above, the cache mode is set to writeback. I booted up this guest and checked the mount options:
If I needed to tweak anything, I would edit /etc/fstab, reboot the VM, and then check /proc/mounts again. Right now it is using the default commit=5 and barrier=1 values since neither is listed above. We are ready to test.
To verify that the guest is flushing its data to permanent storage every 5 seconds, we need to check for the presence of fdatasync() calls. Fortunately, QEMU/KVM makes this easy since the entire VM runs as a normal process on the host. First, in the guest, start writing some data to disk:
1# while [ 1 ]; do date >> /root/test.txt; done
Let's use strace on the host to check after we've located the PID for the qemu-system-x86_64 process:
1$ sudo strace --timestamps=unix -e trace=fdatasync -f -p 27380
2[pid 32511] 1720820043 fdatasync(14) = 0
3[pid 32510] 1720820043 fdatasync(14) = 0
4[pid 32508] 1720820048 fdatasync(14) = 0
5[pid 32511] 1720820048 fdatasync(14) = 0
6[pid 32510] 1720820053 fdatasync(14) = 0
7[pid 32511] 1720820053 fdatasync(14) = 0
8[pid 32508] 1720820053 fdatasync(14) = 0
9[pid 32510] 1720820058 fdatasync(14) = 0
10[pid 32511] 1720820058 fdatasync(14) = 0
11[pid 32508] 1720820058 fdatasync(14) = 0
12[pid 32510] 1720820058 fdatasync(14) = 0
13[pid 32511] 1720820063 fdatasync(14) = 0
14[pid 32508] 1720820063 fdatasync(14) = 0
Sure enough, fdatasync() syscalls are coming through every 5 seconds, matching the commit=5 mount parameter in the guest!
Putting It All Together
We now understand how ext4 ensures that writes are written to disk to preserve data integrity using the journal, the commit mount option, and write barriers. Moreover, we can confirm that writes in a VM act like they do on a physical server when the QEMU disk mode is set to writeback. No matter if it is a physical server or a VM, there is a period of time where data may be lost during a power outage, however the journal ensures that the filesystem remains consistent even in this case.